 RSS dovod
RSS dovodStari sertifikati MUPCA u kojima je kao izdavalac upisan „MUPCA Građani“ ili „MUPCA Građani 2“ imaju poznati propust gde su serijski brojevi sertifikata neispavno zapisani sa vodećim nulama, suprotno standardu za X.509 sertifikate i pravilima ASN.1 kodiranja. Za problem se zna od 2010. godine. MUP je 2014. godine prešao na nove sertifikate i oni u kojima je kao izdavalac upisan „MUPCA Građani 3“ su ispravni i nemaju ovaj problem.
Nije mi poznato koliko starih sertifikata je još uvek važeće, niti da li je moguće dobiti novi sertifikat na ličnoj karti sa starim čipom (kartice izdate pre 18.8.2014).
Problem sa starim sertifikatima u nekim programima sprečava njihovo korišćenje. Za korišćenje u bilo kom programu zasnovanom na openssl biblioteci (na primer prijava klijentskim sertifikatom na veb serveru) potrebno je koristiti posebno prepravljenu openssl biblioteku.
Nova verzija Jave 8u121 objavljena 17. januara ove godine kao ispravku nepovezanog sigurnosnog propusta dodaje i proveru koja ove stare sertifikate čini neupotrebljivim u programima zasnovanim na Javi. Izmena nosi oznaku JDK-8168714 i uključena je u Java 8 u121, Java 7 u131, Java 6 u141 i sva novija izdanja, uključujući i OpenJDK distribuciju Jave.
More checks added to DER encoding parsing code to catch various encoding errors. In addition, signatures which contain constructed indefinite length encoding will now lead to IOException during parsing. Note that signatures generated using JDK default providers are not affected by this change. (JDK-8168714)
Za korisnike ovo znači da kada se izvrši ažuriranje Jave servisi ePorezi ili CROSO više ne rade sa starim sertifikatima MUP-a koji kao izdavaoca imaju MUPCA Građani ili MUPCA Građani 2. Na servisu ePorezi ne vidi se konkretna greška već uopštena poruka „Na kartici ne postoji sertifikat sa podacima o JMBG“ koja može da označava i druge probleme. Na CROSO portalu se prikazuje tačna greška „Invalid encoding: redundant leading 0s“ koja nam ukazuje na problem.
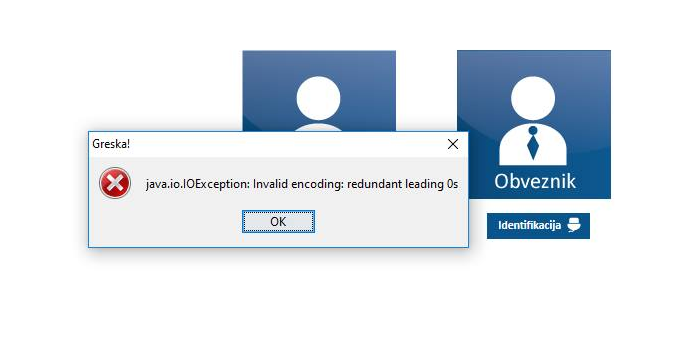
Rešenje je zamena sertifikata novim čiji je izdavalac MUPCA Građani 3, ili privremeno vraćanje Jave na stariju verziju 8u112. Instalacija starije Java 8u112 za Windows je dostupna ovde ili prateći Java Archive link na zvaničnom Oracle sajtu.
Java veb aplikacije
Nadogradnja Java okruženja će pogoditi i sve veb aplikacije koje čuvaju, primaju ili validiraju sertifikate i potpise. Problem možemo da ilustrujemo trivijalnim kodom koji učitava X.509 sertifikat:
import java.io.FileInputStream;
import java.security.cert.Certificate;
import java.security.cert.CertificateFactory;
public class LoadCert {
public static void main(String args[]) throws Exception {
FileInputStream in = new FileInputStream(args[0]);
CertificateFactory cf = CertificateFactory.getInstance("X.509");
Certificate trust = cf.generateCertificate(in);
System.out.println("ok");
}
}
$ java -version openjdk version "1.8.0_121" OpenJDK Runtime Environment (build 1.8.0_121-8u121-b13-0ubuntu1.16.10.2-b13) OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode) $ java LoadCert MUPCARoot.crt Exception in thread "main" java.security.cert.CertificateParsingException: java.io.IOException: Invalid encoding: redundant leading 0s at sun.security.x509.X509CertInfo.<init>(X509CertInfo.java:169) at sun.security.x509.X509CertImpl.parse(X509CertImpl.java:1804) at sun.security.x509.X509CertImpl.<init>(X509CertImpl.java:195) at sun.security.provider.X509Factory.engineGenerateCertificate(X509Factory.java:102) at java.security.cert.CertificateFactory.generateCertificate(CertificateFactory.java:339) at MainClass.main(MainClass.java:27) Caused by: java.io.IOException: Invalid encoding: redundant leading 0s at sun.security.util.DerInputBuffer.getBigInteger(DerInputBuffer.java:152) at sun.security.util.DerValue.getBigInteger(DerValue.java:512) at sun.security.x509.SerialNumber.construct(SerialNumber.java:44) at sun.security.x509.SerialNumber.<init>(SerialNumber.java:86) at sun.security.x509.CertificateSerialNumber.<init>(CertificateSerialNumber.java:102) at sun.security.x509.X509CertInfo.parse(X509CertInfo.java:643) at sun.security.x509.X509CertInfo.<init>(X509CertInfo.java:167) ... 5 more $ java LoadCert MUPCARoot3.crt ok
Na staroj verziji Jave 8u112, oba sertifikata se ispravno učitavaju:
$ $JAVA_HOME/bin/java -version java version "1.8.0_112" Java(TM) SE Runtime Environment (build 1.8.0_112-b15) Java HotSpot(TM) 64-Bit Server VM (build 25.112-b15, mixed mode) $ java LoadCert MUPCARoot.crt ok $ java LoadCert MUPCARoot3.crt ok
Moguće zaobilazno rešenje je prirediti poseban JRE koji ne sadrži proveru dodatu kroz JDK-8168714, ali sadrži druge bezbednosne ispravke.
Ispravka dolazi u sigurnosnim nadogradnjama za RHEL verzija 5, 6 i 7 kao i za sve druge poznate distribucije, odnosno drugi softver koji sadrži zakrpu za CVE-2016-5546, pa se može dogoditi da se verzija Jave nadogradi i ako ne menjate postavke svoje aplikacije.
Ovaj citat odlično opisuje situaciju:
